¿Querido ChatGPT o Dear ChatGPT?
Explorando las diferencias en el comportamiento de los modelos de lenguaje en distintos idiomas.
En los últimos años mi trabajo ha sido principalmente en inglés, así que mi uso de la mayoría de modelos de lenguaje ha sido en ese idioma. Por pura inercia, he continuado usando estos modelos en inglés incluso fuera del ámbito laboral. Sin embargo, mi lengua materna es el español. ¿Me estoy perdiendo de algo utilizando solo en inglés los modelos de lenguaje? Este artículo explora las diferencias en el desempeño de los modelos de lenguaje cuando se utilizan en distintos idiomas, y analiza las razones que podrían explicar estas variaciones.
Las ciudades que debería visitar antes de morir
Empecemos con un ejemplo sencillo. Usando ChatGPT (con el modelo GPT4-o), quiero tener una respuesta a la pregunta: ¿Cuáles son las 5 ciudades del mundo que debo visitar antes de morir? Haciendo la pregunta en español obtenemos lo siguiente:

Diagrama 1. Ciudades para visitar, en español.
No aparece Bogotá 😔. En inglés obtenemos lo siguiente:
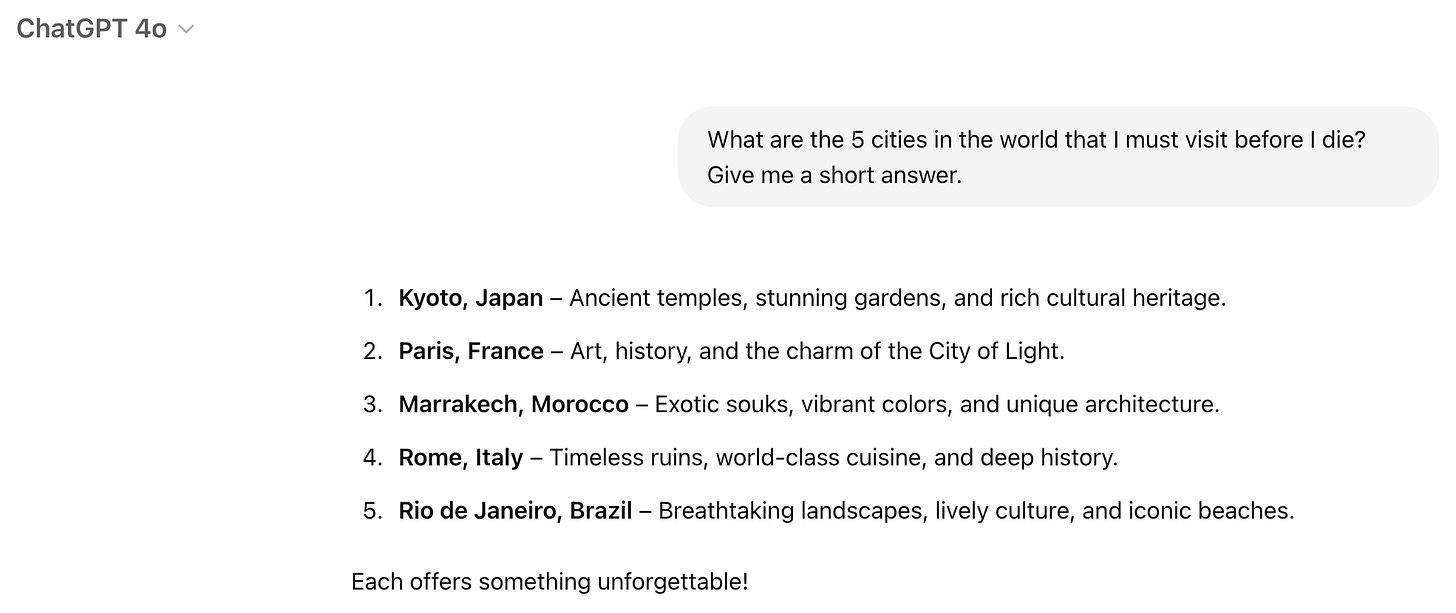
Diagrama 2. Ciudades para visitar, respuesta en inglés.
Si bien el formato de la respuesta es muy similar, hay varias diferencias que vale la pena resaltar.
-
Diferentes ciudades: Tres de las ciudades (Kyoto, Marrakech y Roma) están en ambas listas pero hay discrepancia en las otras dos.
-
Diferentes descripciones: Para las tres ciudades en común la descripción de los atractivos de la ciudad no es la misma. En español se destaca el arte de Roma mientras que en inglés se habla de una “historia profunda”.
-
Cierre: En inglés tenemos un pequeño cierre entusiasta diciendo que cada ciudad ofrece algo inolvidable. En español no.
El ejemplo puede ser un poco trivial pero nos ayuda a ver que las respuestas del modelo no son estables a través de los idiomas. Una pregunta idéntica, traducida a otro idioma, puede generar resultados notablemente diferentes.
De hecho, las respuestas ni siquiera son estables en el mismo idioma. Si hacemos la misma pregunta varias veces en español, es probable que obtengamos listas de ciudades ligeramente diferentes cada vez; inténtenlo ustedes. Esto se debe a la naturaleza probabilística de la generación del texto y al parámetro de temperatura que controla el nivel de aleatoriedad en las respuestas. Una temperatura más alta lleva al modelo a seleccionar con más frecuencia palabras que en principio tienen una probabilidad menor de ser elegidas (este será el tema de uno de los siguientes artículos pero mientras tanto les dejo este demo interactivo).
Quedémonos, sin embargo, con las diferencias entre las respuestas en los dos idiomas: ¿de dónde pueden venir?
Diferentes datos, diferentes resultados
Los modelos de lenguaje necesitan una gran cantidad de datos para ser entrenados. Estos datos consisten principalmente de fragmentos de texto recolectados de todos los lugares posibles (libros, páginas web, etc.). El problema está en la representación desigual de los idiomas dentro de estos fragmentos de texto utilizados para el entrenamiento.
Dado que muy pocas empresas son transparentes con los datos que usan para entrenar sus modelos es imposible saber exactamente la distribución de los idiomas en los datos de entrenamiento de los modelos más populares.
Incluso las empresas que dan acceso libre a sus modelos (como Meta con el modelo LLaMA), no hacen públicos los datos. Dos excepciones que vale la pena nombrar son HuggingFace 🤗 y Ai2. En particular, HuggingFace provee acceso a una serie de bases de datos que nos pueden ayudar a responder a nuestra pregunta. Fineweb y su versión multilingüe, Fineweb-2, son de las mayores bases de datos abiertas con texto extraído de la web, lo que las hace útiles para estimar la disponibilidad de datos por idioma en el entrenamiento de modelos de lenguaje. Aunque no reflejan exactamente los datos usados en modelos comerciales, ofrecen un punto de referencia útil.
Fineweb contiene 51 terabytes (TB) de texto en inglés, una unidad de medida que representa el tamaño de los datos almacenados. Ninguno de los más de 100 idiomas presentes en Fineweb-2 se acerca a esta cifra. Los cinco idiomas con mayor representación son:
-
Ruso: 1.65 TB de datos (3% de los datos en inglés)
-
Chino mandarín: 1.34 TB de datos (2.6% de los datos en inglés)
-
Alemán: 0.64 TB de datos (1.2% de los datos en inglés)
-
Japonés: 0.64 TB de datos (1.2% de los datos en inglés)
-
Español: 0.54 TB de datos (1% de los datos en inglés)
Las diferencias son significativas. Los datos disponibles en español son solo el 1% de los que existen en inglés (y aún así el español está en el top cinco). Probablemente la diferencia sea aún más grande en los datos en los que se entrenan los modelos más populares. Esto marca una primera gran diferencia que, como veremos en la última sección del artículo, parece tener efectos sobre el rendimiento de los modelos.
Más allá de la cantidad, es razonable pensar que el tipo de contenido también es diferente dependiendo del idioma. Esto significa que la representación del conocimiento puede variar significativamente según el idioma utilizado. Por ejemplo, es posible que el modelo haya visto más contenido turístico sobre ciertas ciudades en inglés que en español, lo que influye en las recomendaciones que hace en cada idioma.
Además, las diferencias culturales implícitas en cada idioma pueden llevar al modelo a enfatizar aspectos distintos según el contexto lingüístico. Las preferencias de viaje y los puntos de interés considerados importantes pueden variar entre comunidades lingüísticas, y estas sutilezas quedan reflejadas en los datos de entrenamiento y, consecuentemente, en las respuestas del modelo.
Diferencias provenientes de las fuentes consultadas; el caso de la guerra entre Rusia y Ucrania
Miremos ahora un ejemplo con una capa de complejidad adicional. Le pediremos al modelo un resumen de un evento de actualidad. En el caso de ChatGPT esto hará que el modelo inicie una búsqueda de fuentes en internet (OpenAI explica esta funcionalidad acá).
Como vimos en el artículo de la semana pasada, los modelos de lenguaje no son buscadores de información del mismo estilo que Google, sino que son generadores de texto a partir de las probabilidades aprendidas en los datos de entrenamiento. Sin embargo, sistemas como ChatGPT o Perplexity han incorporado la posibilidad de hacer búsquedas explícitas de fuentes en internet y producir respuestas incorporando las fuentes encontradas.
En ChatGPT esto se puede hacer explícitamente dando click sobre el botón de “Buscar”:
Diagrama 3. Función de búsqueda en ChatGPT.
Es posible también que la búsqueda en internet se active de manera automática. Por lo general esto pasa cuando se hacen preguntas sobre temas de actualidad. Una vez hecha la pregunta, la interfaz mostrará el texto de “Buscando en internet” y al cabo de unos segundos podrán aparecer algunos logos indicando las fuentes consultadas. En el Diagrama 4 vemos, por ejemplo, que aparecen los logos de ESPN, AS y Youtube después de hacer una pregunta sobre el resultado de un partido de fútbol.
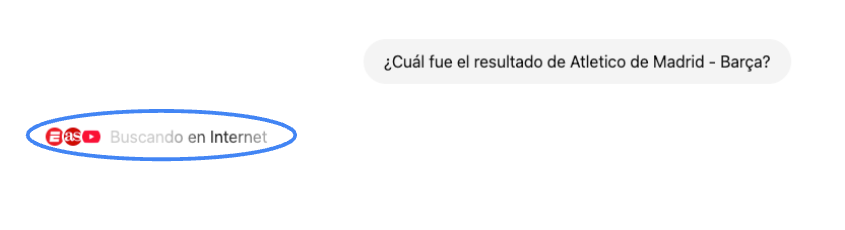
Diagrama 4. Función de búsqueda automáticamente iniciada por ChatGPT.
Es clave entender en qué momentos el sistema está dando respuestas sin consultar fuentes externas y en qué momentos las respuestas se dan después de un proceso de búsqueda en internet.
Centrémonos ahora en un ejemplo de mucha relevancia y complejidad: la guerra entre Rusia y Ucrania. Al preguntar al modelo en español: ¿Cuál es el estado actual de la guerra entre Rusia y Ucrania?, este realiza una búsqueda de fuentes en internet y genera la siguiente respuesta:

Diagrama 5. Estado actual de la guerra, respuesta en español.
Al final de cada párrafo se resalta la fuente que el modelo utilizó para generar la respuesta. En inglés obtenemos lo siguiente:

Diagrama 6. Estado actual de la guerra, respuesta en inglés.
En la respuesta en español, se destaca el uso de cazas franceses Mirage-2000 por parte de Ucrania y se menciona específicamente la postura del presidente Trump, quien amenaza con imponer sanciones "a gran escala" hasta que se alcance un acuerdo de paz. También se incluyen cifras de víctimas desde el inicio del conflicto (entre 174.000 y 420.000 personas).
En contraste, la respuesta en inglés enfatiza la suspensión de ayuda militar estadounidense y el impacto en las capacidades operativas de Ucrania, mencionando además una posible retirada ucraniana de la región rusa de Kursk, información que está completamente ausente en la versión española.
La diferencia más notable entre ambas respuestas parece provenir de las fuentes citadas. En la respuesta en español se mencionan medios como cadenaser.com, elpais.com y huffingtonpost.es, mientras que en inglés se citan apnews.com, The New Yorker y New York Post. Esta variación en las fuentes consultadas es posiblemente la causa principal de las importantes diferencias en la información proporcionada.
Más allá de los ejemplos particulares
Para cerrar, quiero hacer referencia a algunas publicaciones académicas recientes que han estudiado a profundidad el tema de las diferencias en el rendimiento de los modelos de lenguaje en distintos idiomas. Para hacer esto, los autores han evaluado los modelos en una variedad de tareas para las que existen datos de evaluación (razonamiento, respuesta a preguntas, resumen de textos, etc.).
Académicos como Ahuja y coautores (2024) o Dac Lai y coautores (2023) encuentran que los modelos de lenguaje tienen el mejor rendimiento en lenguas de la familia germánica (ej. inglés, alemán, sueco). En segundo lugar están las lenguas de la familia romance (ej. español, francés, italiano). Además, la mayoría de modelos de lenguaje tienen peor rendimiento en lenguajes con alfabetos no latinos y lenguajes con pocos recursos. Estos hallazgos son consistentes con el informe de política de Cohere (2024) The AI Language Gap que destaca la brecha significativa entre los idiomas dominantes y aquellos con menor representación en los datos de entrenamiento.
Esta disparidad no es solo una cuestión técnica sino también un problema de equidad digital. Las personas que hablan idiomas menos representados tienen acceso a versiones menos capaces de estas tecnologías, limitando potencialmente sus beneficios en áreas como la educación, la salud y el acceso a la información.
A raíz de esto, recientemente algunas empresas han hecho énfasis en desarrollar modelos de lenguaje específicamente pensados para diversos idiomas. Dos ejemplos interesantes son:
-
Saba: Lanzado por Mistral AI, este modelo ha sido diseñado específicamente para mejorar el rendimiento en árabe y otros idiomas de Oriente Medio y Norte de África (MENA). Saba representa un esfuerzo por crear modelos con una comprensión profunda de los matices culturales y lingüísticos de estas regiones.
-
Aya: Desarrollado por Cohere, Aya es un modelo multilingüe de código abierto que busca mejorar el procesamiento del lenguaje natural en más de 100 idiomas. Lo notable de Aya es su enfoque en idiomas tradicionalmente subrepresentados, buscando democratizar el acceso a la tecnología LLM.
Conclusión
Los modelos de lenguaje ofrecen experiencias diferentes según el idioma utilizado, influenciados por la cantidad y tipo de datos de entrenamiento, las fuentes consultadas y los matices culturales inherentes a cada lengua. Si bien no tenemos acceso a los datos utilizados por los desarrolladores de los modelos más populares, las bases de datos abiertas nos muestran un fuerte dominio del inglés. Este desequilibrio en los datos de entrenamiento resulta en un mejor rendimiento de los modelos en este idioma. Esfuerzos recientes como Mistral Saba y Aya de Cohere buscan contrarrestar esta tendencia, desarrollando modelos específicamente enfocados en mejorar el rendimiento para idiomas tradicionalmente subrepresentados.
Usar los modelos en distintos idiomas es solo una forma más de notar lo inestables y cambiantes que pueden ser estos modelos. Esta variabilidad no solo refleja limitaciones técnicas, sino también importantes consideraciones sobre equidad y acceso.