Los modelos de lenguaje no son buscadores (o no como los entendemos tradicionalmente)
Una breve reflexión sobre las diferencias entre estas dos tecnologías y los problemas de usar ChatGPT como si fuera el buscador de Google.
Los buscadores como Google, Bing o Yahoo! han sido la manera en que tradicionalmente hemos encontrado el contenido digital que buscamos. Si bien estos todavía representan la mayor parte de las búsquedas en internet, cada vez más personas usan modelos de lenguaje para obtener respuestas a sus preguntas. En el artículo de esta semana quiero explorar las diferencias entre estas dos tecnologías y los problemas que tiene utilizar los modelos de lenguaje como si fueran buscadores.
¿Qué es un buscador exactamente?
Para entender las diferencias entre un modelo de lenguaje y un buscador, tenemos que empezar por aclarar qué son y cómo funcionan los buscadores. Google es, sin duda, el más conocido y el más utilizado con una cuota de mercado de alrededor del 80% (Statista, 2025).
Si bien cada buscador tiene sus ingredientes secretos, la lógica general de estos sistemas es similar. La idea es encontrar los sitios web más relevantes para la búsqueda específica de un usuario. Para hacer esto, las empresas detrás de los buscadores tienen que estar constantemente rastreando la web para incluir en sus bases de datos todas las páginas web nuevas y mantener el contenido de estas actualizado. Pero, ¿cómo saber si un sitio es relevante? Los buscadores como Google usan una combinación de información para descifrar esto:
-
Coincidencia entre la búsqueda y el contenido de la página: El buscador analiza si las palabras de la búsqueda del usuario (o palabras similares) aparecen en el título, la descripción, los encabezados o el contenido de la página.
-
Reputación de la página: El algoritmo fundacional de Google (PageRank) se basa en la idea de que la importancia de una página puede medirse por la cantidad de otras páginas que apuntaban a ella. Por ejemplo, si muchas páginas web incluyen links a los artículos de Loras Mojadas, Google empezará a considerar esa página como de alta reputación (🤞).
-
Información personal del usuario: Si el usuario está en Bogotá, los resultados para una búsqueda sobre “mejores arepas” van a ser muy diferentes que si el usuario está en Barcelona.
Para los interesados en conocer mejor los detalles del algoritmo de Google les dejo dos recursos interesantes:
Las diferencias con un modelo de lenguaje
Un modelo de lenguaje funciona de forma muy diferente a un buscador. Como expliqué en mi primer artículo, estos modelos generan texto nuevo seleccionando palabra por palabra las de mayor probabilidad. Estas probabilidades provienen de un proceso de pre-entrenamiento donde el modelo es entrenado con millones de fragmentos de texto.
De entrada, esto marca una gran diferencia entre los buscadores y los modelos de lenguaje: los primeros responden a la búsqueda de un usuario con fuentes primarias para que el usuario consulte, mientras que los segundos responden directamente a la búsqueda del usuario.
En lo que queda del artículo, desarrollo algunos de los problemas que se desprenden de esta diferencia fundamental entre los buscadores y los modelos de lenguaje.
Apariencia de certeza y falta de referencia a las fuentes
Los modelos de lenguaje responden a casi cualquier pregunta, sin importar su dificultad o complejidad, dando una impresión de certeza y confianza. En el Diagrama 1, le pido a Claude un resumen del conflicto armado en Colombia. Si bien la respuesta reconoce la complejidad del fenómeno, esta transmite un alto grado de certeza.

Diagrama 1. Pregunta a Claude sobre el conflicto colombiano.
Además, el modelo no menciona ninguna de las fuentes que usa para sus afirmaciones. Una búsqueda similar en Google, por el contrario, muestra fuentes de El Centro de Memoria Histórica, Wikipedia, La revista Desafíos de la Universidad del Rosario y videos de YouTube de France24.
Acceso a información reciente
Los modelos de lenguaje requieren varios meses para ser entrenados. Esto significa que, para el momento que los modelos están disponibles al público, el corpus de texto con el que se entrenaron tiene ya varios meses de desactualización. Así que si le pregunto a un modelo de lenguaje por hechos recientes, no obtendré respuestas actualizadas o precisas. Miremos un ejemplo. En el Diagrama 2 le pregunto a Claude por la muerte de Mario Vargas Llosa y obtengo lo siguiente:

Diagrama 2. Pregunta sobre muerte de Vargas Llosa a Claude.
Es interesante que el modelo reconoce el límite temporal de la información con la que fue entrenado. Sin embargo, la respuesta no es útil porque no nos proporciona la información actualizada que necesitamos. El problema es aún peor en ChatGPT que afirma con certeza que Vargas Llosa sigue vivo cuando no lo está.

Diagrama 3. Pregunta sobre muerte de Vargas Llosa a ChatGPT.
Alucinaciones
El problema de acceso a información reciente puede ser resuelto dándole al modelo de lenguaje acceso a internet. Esto es exactamente lo que la funcionalidad de “Buscar” hace en ChatGPT (acá el artículo completo de OpenAI).
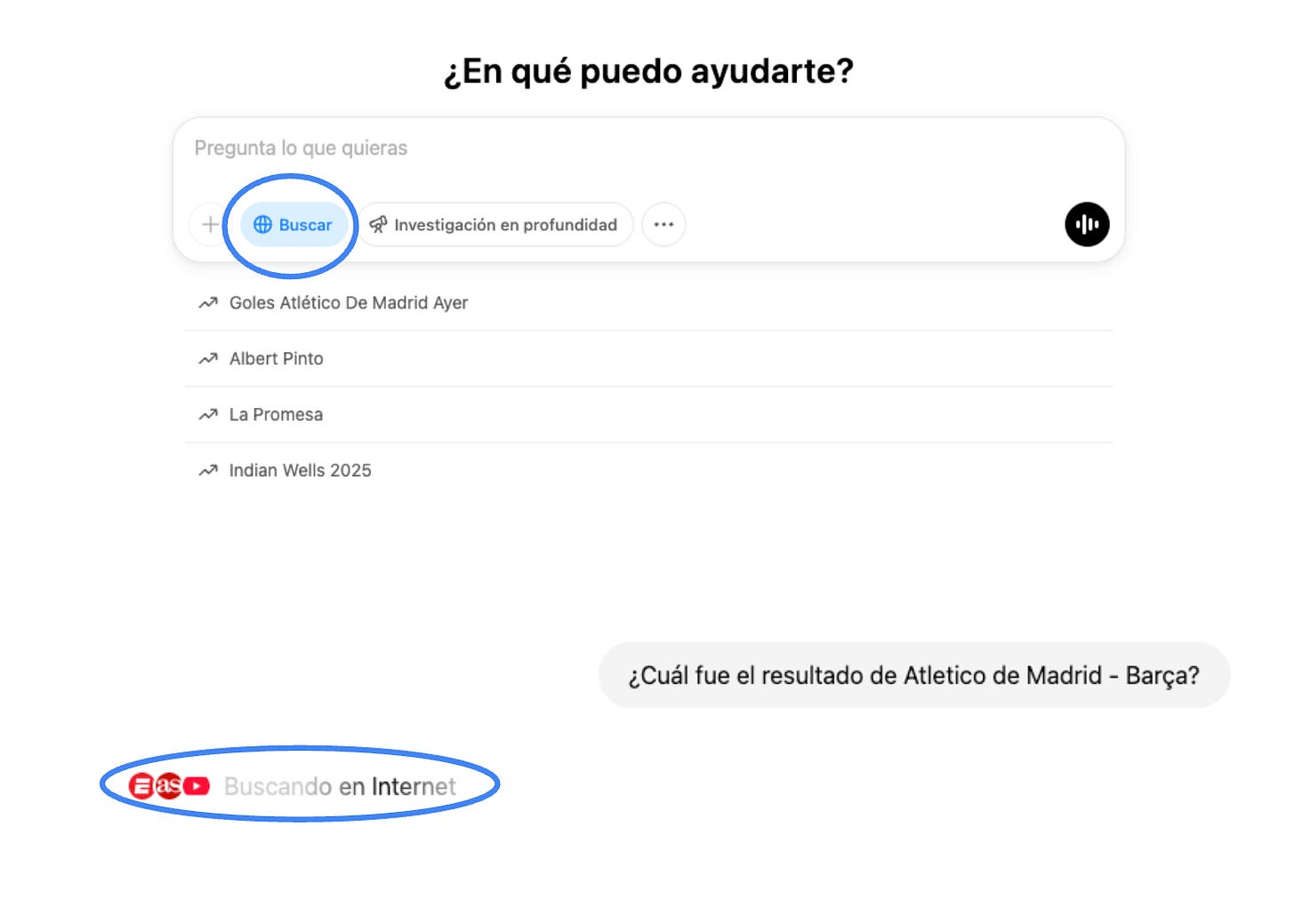
Diagrama 4. Funcionalidad de Buscar en ChatGPT.
Sin embargo, incluso los modelos más avanzados pueden alucinar, generando información falsa o inventada que parece plausible. Incluso consultando las fuentes correctas, el modelo puede generar resúmenes inadecuados o utilizar partes irrelevantes del texto para generar respuestas.
Nuevas fronteras
Aunque durante todo el artículo hemos hablado de los modelos de lenguaje y los buscadores como dos tecnologías totalmente separadas, hay varias razones para pensar que cada vez existirá más integración entre ellas. Google, por ejemplo, está integrando modelos de lenguaje directamente en su buscador:
- Fragmentos destacados: Google utiliza un modelo de lenguaje para encontrar el fragmento dentro de un sitio web que responde a la búsqueda del usuario (acá el artículo de Google).
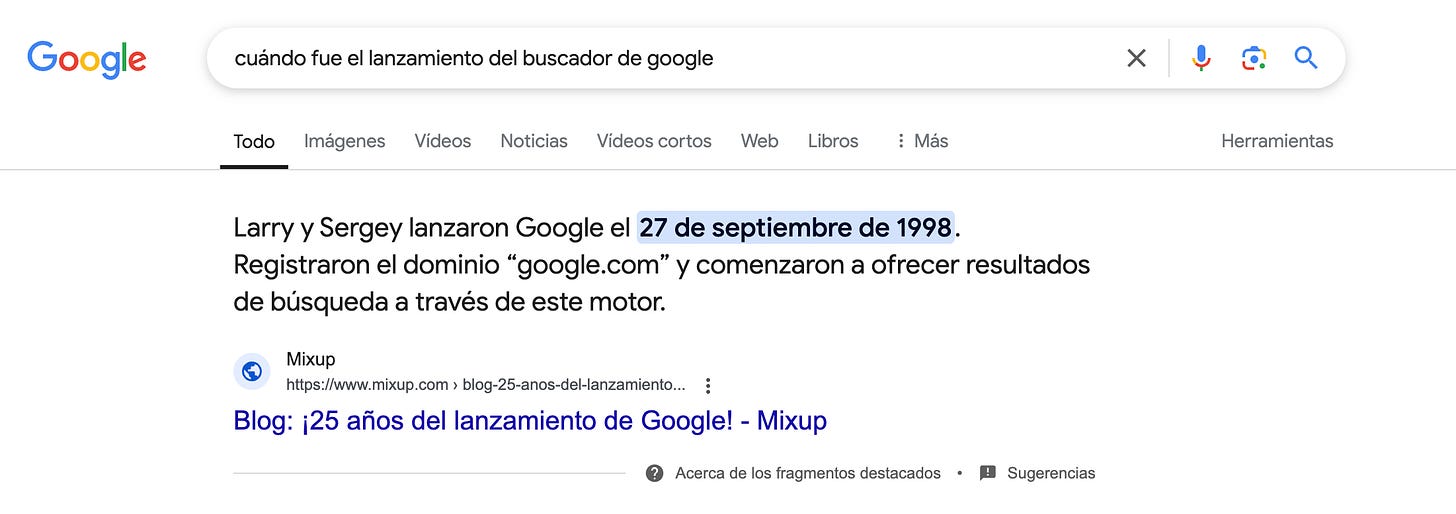
Diagrama 5. Fragmentos destacados de Google.
- Modo Inteligencia Artificial: Google ha introducido un "modo IA" en su buscador que busca generar directamente respuestas a las búsquedas de los usuarios (ver anuncio de Google).
Por otro lado, algunos modelos de lenguaje están usando herramientas de búsqueda para complementar sus capacidades:
-
Perplexity: Combina búsquedas web con generación de texto usando modelos de lenguaje, proporcionando respuestas actualizadas con fuentes claras.
-
Integración de búsqueda en ChatGPT y Claude: Como mencioné en la sección anterior, OpenAI integró directamente en ChatGPT la capacidad de hacer búsquedas en internet. Anthropic lanzó recientemente una funcionalidad similar para Claude.
Conclusión
Aunque los modelos de lenguaje ofrecen una interacción intuitiva y una capacidad impresionante para generar texto coherente, es fundamental entender sus limitaciones. No son buscadores en el sentido tradicional: carecen de acceso a información actualizada en tiempo real, pueden presentar información errónea con gran certeza y no están diseñados para citar fuentes. El panorama está cambiando rápidamente, con empresas como Google integrando cada vez más modelos de lenguaje en sus productos. Aun así, entender la diferencia entre estas dos tecnologías sigue siendo clave para usarlas bien.
Invitación
El próximo sábado 26 de abril a las 9 a.m. hora Colombia (4 p.m. hora Europa central) voy a hacer el primer curso de Loras Mojadas. Voy a empezar con un curso de 1 hora y media sobre herramientas de búsqueda y contexto. La idea es explicar cómo funcionan estas herramientas y hacer una demostración práctica de cómo usarlas. En este curso veremos Perplexity, NotebookLM y algunas formas de darle más contexto a un modelo de lenguaje como ChatGPT. Para este curso solo se necesita un computador con acceso a internet y una cuenta de Google.
Se pueden inscribir acá: