El mecanismo detrás de los modelos de lenguaje
¿Cómo hacen los modelos de lenguaje para generar texto? La idea fundamental es simple pero increíblemente poderosa.
La mayoría de nosotros usamos algún modelo de lenguaje como parte de nuestra vida diaria. Yo, por ejemplo, uso estos modelos para redactar correos o generar fragmentos de código (puede que también para revisar partes de los artículos que publico 😉). El funcionamiento de estos modelos no es para nada evidente. ¿Cómo hacen para generar texto? ¿Qué está pasando detrás de la interfaz que vemos en aplicaciones como ChatGPT? La idea de este artículo es dar una primera respuesta a estas preguntas.
¿Qué son los modelos de lenguaje?
Los modelos de lenguaje (LLM en inglés) son, en esencia, máquinas de predecir palabras nuevas a partir de un contexto. Estos modelos, utilizan el contexto brindado por el usuario para responder una sola pregunta: ¿cuál es la palabra con la mayor probabilidad de ser la siguiente? Para responder a esta pregunta, el modelo sigue una serie de pasos:
-
Representa todas las palabras que hacen parte del contexto de forma numérica.
-
Estima una probabilidad para cada palabra del vocabulario al combinar la representación numérica del contexto con los patrones aprendidos en los datos de entrenamiento (más sobre esto en la siguiente sección).
-
Elige una palabra según las probabilidades calculadas.
Una vez elegida la palabra nueva, el proceso se repite. Es así como estos modelos pueden generar fragmentos de texto verdaderamente extensos. Este funcionamiento ha llevado a algunos académicos a llamar a estos modelos loras estocásticas 🦜 (el artículo de Bender y co-autores desarrolla esta idea).
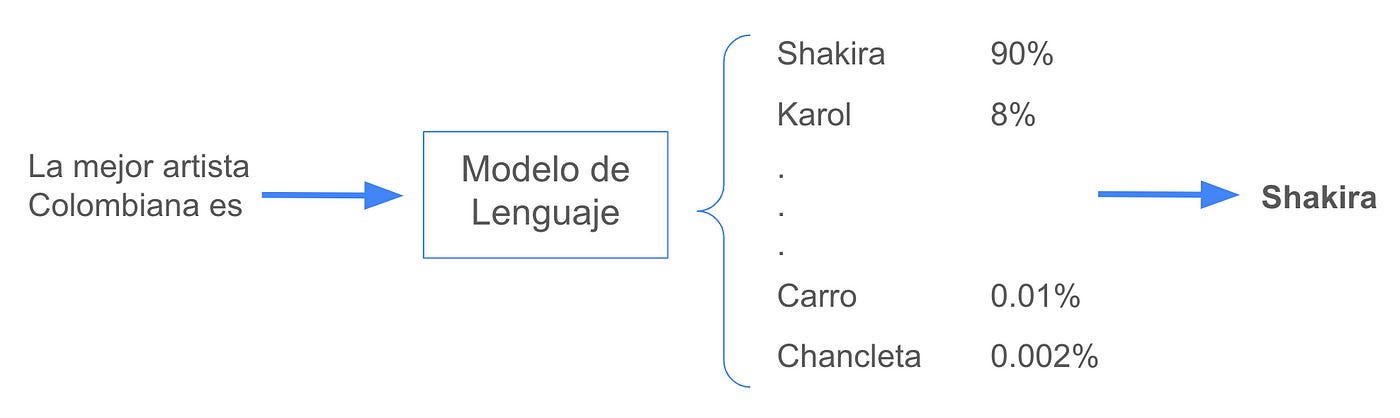
Diagrama 1. El funcionamiento básico de un LLM
El ejemplo muestra como, dado el contexto “La mejor artista colombiana es” el modelo es capaz de calcular, para todas las palabras del vocabulario, la probabilidad de que sean la siguiente. Por supuesto, la palabra con más probabilidad es “Shakira” seguida de “Karol” (el ejemplo no es real pero refleja mis preferencias). En las palabras con menos probabilidad vemos ejemplos como “carro” o “chancleta”; palabras que nada tienen que ver con el contexto.
Para explorar más a fondo esta idea, construí está aplicación que permite:
1. Escoger un modelo de lenguaje público.
2. Introducir palabras de contexto.
3. Ver las palabras con más probabilidad de ser la siguiente en el modelo escogido.
4. Escoger alguna de las palabras con más probabilidad o añadir una palabra nueva.
5. Volver a calcular las probabilidades del modelo.
¿De dónde salen las probabilidades?
Para aprender cómo generar las palabras nuevas de forma adecuada, los modelos necesitan ver millones de ejemplos en donde un fragmento de texto es completado correctamente por una palabra.

Diagrama 2. Los ejemplos de los que aprende un modelo de lenguaje
En vez de crear estos ejemplos desde cero, los investigadores en el campo notaron que simplemente podían utilizar la gran cantidad de texto disponible digitalmente para generar estos ejemplos. Solo era necesario dividir los textos en fragmentos más cortos y quitar la última palabra (esta se almacena por separado). El Diagrama 2 muestra algunos ejemplos del tipo de datos que necesitan estos modelos.
A raíz de esto, las empresas que desarrollan estos modelos se volcaron completamente a recolectar la mayor cantidad de texto posible. Esto ha generado una enorme cantidad de preguntas legales sobre la legitimidad de las prácticas utilizadas (este artículo del New York Times habla sobre el tema). El secreto más grande de estas empresas hoy en día son los datos que usan para sus modelos.
Con estos datos el modelo está listo para ser preentrenado. En términos sencillos, el preentrenamiento es el proceso de ajustar los parámetros del modelo para que este pueda escoger la palabra adecuada cuando le presentemos los ejemplos que creamos (los del Diagrama 2). El modelo es penalizado cuando se equivoca y sus parámetros son modificados para reducir la cantidad de errores que comete. Después de ver muchos ejemplos, los parámetros del modelo empiezan a encontrar los valores que generan la mayor cantidad de respuestas correctas posibles. Los modelos más capaces tiene actualmente billones de parámetros. GPT-4 (el modelo por defecto en ChatGPT) tiene aproximadamente 1.8 trillones de parámetros. La cifra oficial no la sabemos porque OpenAI (la empresa que desarrolla el modelo) no hace pública esta información.
Un ejemplo real
Miremos ahora un ejemplo real que ilustra bien el funcionamiento de estos modelos. Usaremos el modelo GPT-3.5 (uno de los modelos que usó ChatGPT el año pasado) de OpenAI para explorar las palabras con más altas probabilidades en dos contextos muy similares.
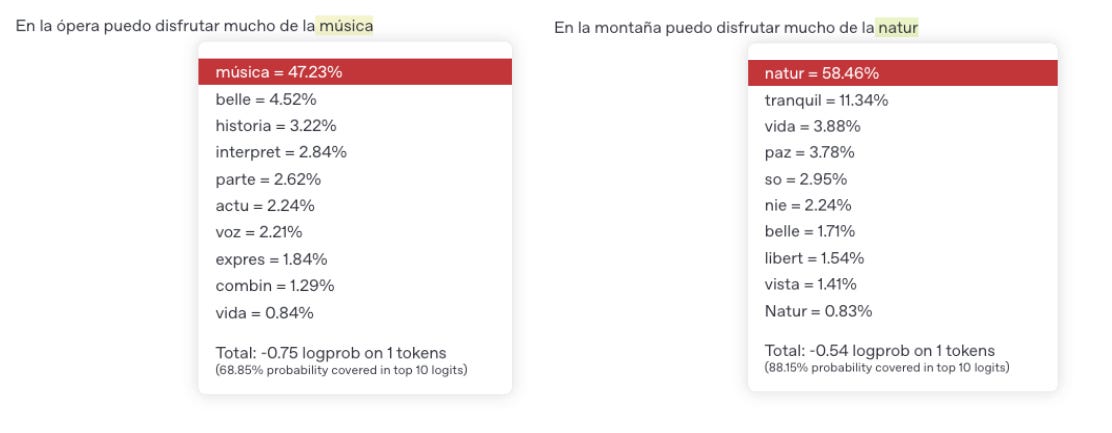
Diagrama 3. Predicciones de un mismo modelo para dos contextos
El ejemplo nos permite ver varias cosas. Primero, en ambos casos las 10 palabras con mayor probabilidad están relacionadas con el contexto de la frase. Segundo, solo cambiar una palabra en el contexto puede tener un efecto muy fuerte sobre la asignación de probabilidades que hace el modelo. Mientras que en el primer caso la palabra “ópera” genera altas probabilidades para palabras como “música” o “historia”, en el caso de “montaña” las palabras con probabilidad más alta son “naturaleza”, “tranquilidad”, “vida” y “paz” (si somos precisos, en realidad el modelo no siempre predice palabras completas, pero esta es una discusión para otro artículo).
Más allá de predecir la siguiente palabra
Hasta ahora hemos visto como los modelos de lenguaje pueden llegar a generar nuevas palabras que se relacionan con el contexto. Si bien esta idea es muy poderosa y hace parte de la esencia de estos modelos, no es suficiente para crear el tipo de comportamientos que vemos en modelos como ChatGPT, Claude o DeepSeek. El Diagrama 4 muestra tres ejemplos reales donde un modelo que solo se centra en predecir la palabra con más probabilidad (GPT-2) genera texto inadecuado con respecto a las expectativas del usuario. En esta página es posible probar cualquier ejemplo.

Diagrama 4. Problemas recurrentes en modelos de lenguaje básicos
Lo interesante de los ejemplos es que en todos los casos el texto que se genera corresponde al contexto pero no responde exactamente a lo que el usuario estaba buscando. Para solventar esto, los investigadores en el campo empezaron a utilizar una técnica denominada aprendizaje por refuerzo con retroalimentación humana (reinforcement learning with human feedback en inglés) en donde se incentiva al modelo a generar texto que se alinea con las preferencias de los humanos. Este proceso es complejo y será el tema de un siguiente artículo. Por ahora, basta con entender que los modelos que utilizamos hoy en día tienen procesos de entrenamiento más complejos que el preentramiento que describí en este artículo.
Conclusión
Aunque su funcionamiento interno puede parecer complejo, la idea central de los modelos de lenguaje es sencilla: predecir la palabra más probable dado un contexto. Quedan, sin embargo, varias preguntas por explorar: ¿Qué sabemos exactamente sobre los datos que se utilizaron para entrenar los modelos más capaces? ¿Cómo funciona exactamente el aprendizaje por refuerzo con retroalimentación humana? ¿Por qué GPT-3.5. predice partes de palabras y no palabras completas? Estas preguntas serán el punto de inicio de algunos de los siguientes artículos.